Klinisk Biokemi i Norden · 1 2016
| 23
ble etablert med parametriske eller ikke-parametriske
metoder. Sannsynligheten for at mer enn to av de 20
resultatene ligger utenfor det sentrale 95%-intervallet
er 7,5%. Sannsynligheten for at mer enn to resultater
ligger utenfor det sentrale 95%-intervallet i to påføl-
gende forsøk er < 1%. Det må da konkluderes med at
forskjellen mellom populasjonene er for stor, og at
lokalt referanseintervall må etableres (1).
Selv om dette virker statistisk solid, overkommelig
og økonomisk sett forsvarlig, så innebærer metoden
en del begrensninger som er lite omtalt i litteraturen.
Metoden er godt egnet for å detektere en forskyvning
av gjennomsnittet av symmetriske fordelinger, men
ikke av asymmetriske fordelinger. Data fra referanse-
intervallstudier viser ofte asymmetriske fordelinger
(for eksempel enzymer), noe som gjør vurderingen
mer vanskelig. I tillegg er metoden godt egnet til å
detektere en økning av fordelingens spredning, men
den er ikke egnet til å detektere en reduksjon av
spredningen. Hvis ingen av de 20 resultatene ligger
utenfor referanseintervallet kan det tyde på at det
enten er for vidt eller at fordelingen av eget datasett
er mer homogen enn det originale datasettet, noe som
medfører mindre spredning (fig. 1).
For analytter der referanseintervallet er kritisk
for en klinisk vurdering eller beslutning anbefales
en utvidet verifisering med et høyere antall indivi-
der («extended validation»), for eksempel 60 prøver.
Den utvidete verifiseringen har mer statistisk tyngde
enn en begrenset verifisering. Det forventes at eget
datasett med mange resultater har statistiske egen-
skaper som er representative for hele laboratoriets
populasjon. Ved sammenligning vil i så fall gjen-
nomsnitt og standardavvik i eget datasett ligge veldig
nært gjennomsnitt og standardavvik av den originale
populasjonen som referanseintervallet baserer seg på.
Den utvidete metoden baserer seg på «standard
normal deviate test» og z-verdien, beregnet med
gjennomsnitt og standardavvik, sammenlignes med
en kritisk grenseverdi (z*) (3). Til tross for at bereg-
ningene er relativ enkle å gjennomføre, er det doku-
mentert noen ulemper med metoden (4). Dataene må
være nesten normalfordelt, evt. må de transformeres
først. I tillegg gjenspeiler den estimerte z-scoren ikke
nødvendigvis endene av de to underliggende forde-
lingene. To fordelinger kan ha for eksempel identisk
nedre referansegrense men helt forskjellig øvre refe-
ransegrense dersom standardavvikene er ulike.
Å samle inn et større antall prøver fra friske frivil-
lige individer er mer ressurskrevende enn å samle et
lite antall prøver. Det kan derfor være et alternativ
å etablere egne referanseintervaller med hjelp av
ikke-parametrisk statistikk der man ikke trenger så
mange som 120 individer i hver gruppe, eller ved bruk
av robuste metoder beskrevet av Horn og Pesce (5).
Ved bruk av robuste mål for sentrering og spredning
krever ikke-parametriske og robuste metoder ingen
bestemt fordeling av dataene (1,5).
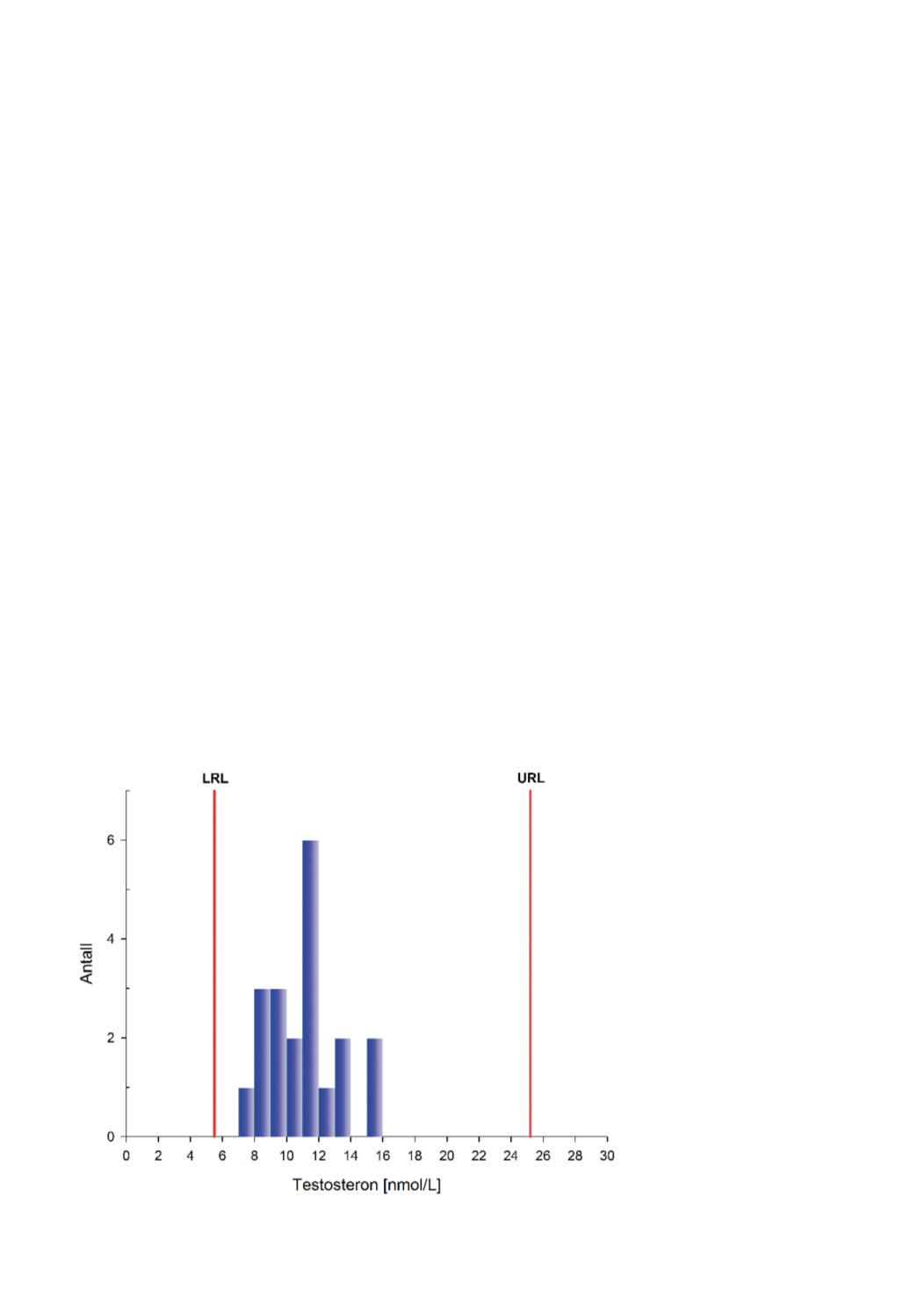
Figur 1: Begrenset verifisering med n=20:
Resultatfordeling for testosteron med nedre
og øvre referanseintervallgrense (rød linje);
(LRL= lower reference limit; URL= upper
reference limit).


