34 |
Klinisk Biokemi i Norden · 3 2020
ningsalgoritmen och lägger till att den ena lösningens
koncentration är uttryckt som absorbans som räknas
om till koncentration med en kalibreringsfunktion.
Modellen är för komplicerad för propageringsmeto-
den och genom att volymsangivelserna uppträder i
både täljare och nämnare duger inte Kragtens ansats.
I den angivna spädningsalgoritmen antas kon-
centrationen bestämd med fotometri och. beräknas
från en ”kalibreringsfunktion” dvs
C
1
=
A-a
b
, där C
1
är koncentrationen, A absorbansen och
a
och
b
är
intercept resp. lutning med osäkerheter uttryckta i
standardavvikelse. Kyvetten antas ha en volym av
0,95 mL (V
1
), vi för över allt innehållet, till en 4,05
mL (V
2
) spädningslösning med koncentrationen 0,5
mmol/L (C
2
) och vi vill uppskatta koncentrationen
i slutlösningen. Osäkerheten i volym och koncentra-
tion är uttryckta i relativ standaravvikelse (%CV).
Antag att vi funnit ett systematiskt fel av -3 % med
en variationskoefficient av 5 %. Formeln blir:
Algoritmen kodas i cellen ”Algorithm”. För tydlighet är
formeln utskriven i figuren på raden under i figur 3.
Resultat
Resultatet av 10
6
itereringar ger ett medelvärde av
0,403 ± 0,029 (%CV:7,2), figur 3.
I figur 4 visas hur simuleringen framskrider dvs
hur medeltalet och standardavvikelen närmar sig
målvärden. Som målvärden har de uppnådda vär-
dena efter 10
6
itereringar valts. Även om de relativa
avvikelserna är mycket små, planar de inte ut förrän
efter omkring 6×10
5
iterationer – i detta exempel.
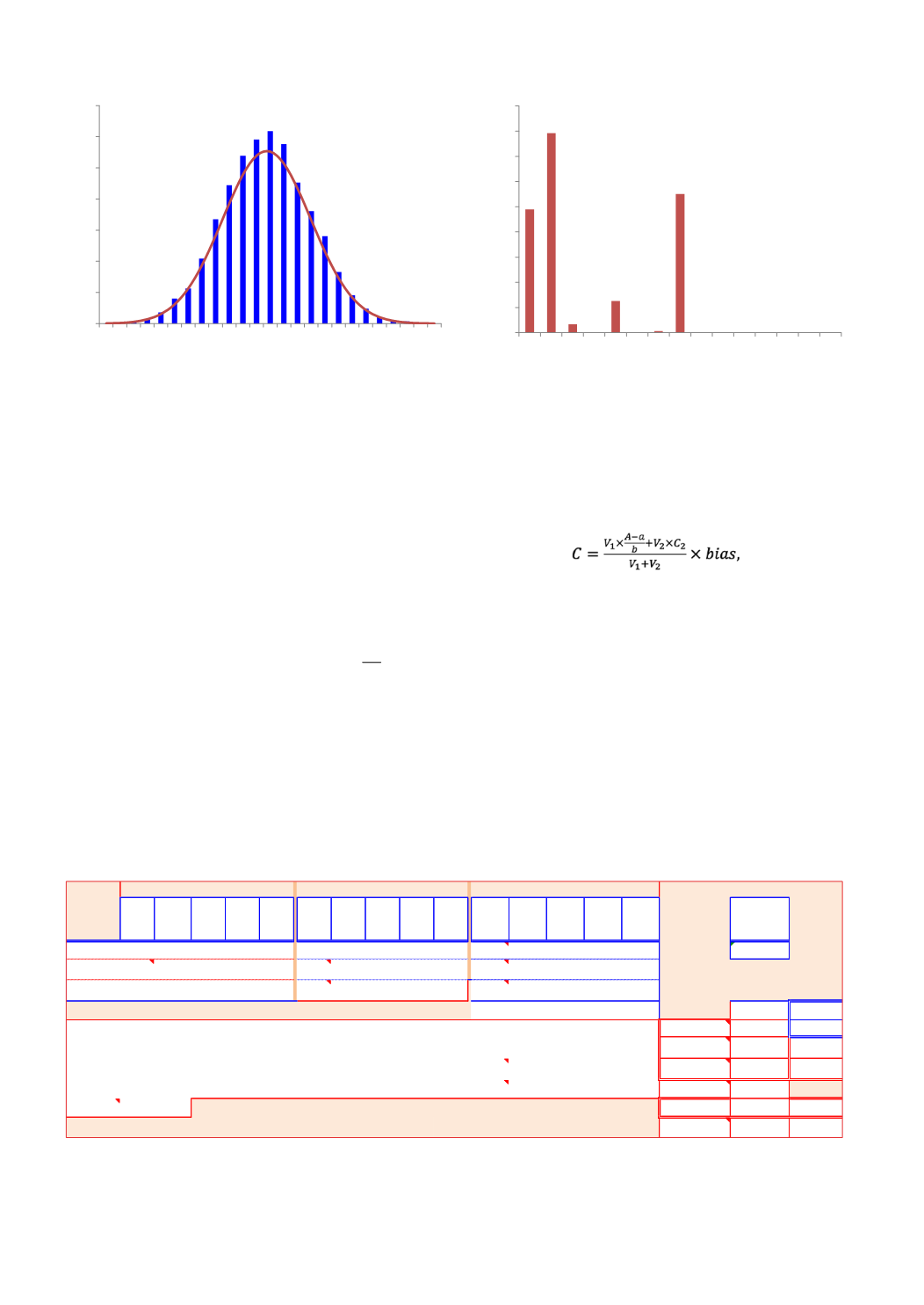
Figur 2.
Histogrammet visar fördelningen av de beräknade resultaten från simuleringen av den givna algoritmen
(10 000 itereringar). Den överlagrade normalfördelningen är beräknad från simulerat medelvärde och standardavvikelse.
Stapeldiagrammet visar de relativa bidragen från osäkerhetskällorna.
Figur 3.
Inmatnings- och resultatdel av simuleringsprogrammet. Text och siffror i rött markerar beräknade storheter, blåa
och violetta är för ”input”.
0
200
400
600
800
1000
1200
1400
0,30
0,31
0,32
0,32
0,33
0,34
0,35
0,36
0,37
0,38
0,39
0,40
0,41
0,41
0,42
0,43
0,44
0,45
0,46
0,47
0,48
0,49
0,49
0,50
0,51
Frequency
Quantity Value
Distribution of simulated values
0
200
400
600
800
1000
1200
1400
0,30
0,31
0,32
0,32
0,33
0,34
0,35
0,36
0,37
0,38
0,39
0,40
0,41
0,41
0,42
0,43
0,44
0,45
0,46
0,47
0,48
0,49
0,49
0,50
0,51
Frequency
Quantity Value
Distribution of simulated values
0,000
0,050
0,100
0,150
0,200
0,250
0,300
0,350
0,400
0,450
C D E F G I
J K L M O P Q R S
Relativest to u(c)
Uncertainty source
Combined uncertainty
Licenced to
V1 V2 C2
Bias
A (a)
(b)
R
Algorithm
Average: 0.950 4.050 0.50
0.97 0.725 0.5 4.10
T
0.403
s(X): 0.095 0.12 0.025
0.05
0.002 0.01 0.10
(C3*(I3-J3)/K3+D3*E3)/(C3+D3)*G3
%CV (%):
10.00 3.00 5.00
5.00
0.3 2.0 2.4
Y
Rectangular (R) or, triangular (T) distribution?
R R R R R
N
k=1
k:
Average:
0.403
2
Average:
1.0 4.0 0.5 0.0 1.0 1 0.5 4.1 0.0 0.0 0.0 0 0.0 0.0 0.0
s(X)=u
c
(X):
0.029 0.058
St dev: 0.096 0.12 0.02 0.00 0.05 0.00 0.01 0.10 0.00 0.00 0.00 0 0.00 0.00 0.00
%CV
c
(X):
7.22
14.4
%CV: 10.12 3.02 5.0
5.0 0 2 2
Number obs 10 000
N:
Interval k: 2 0.345 0.461
CI
95
(s(X)):
0.029 0.029
10 000
Relative uncertainty known Absolute uncertainty known
Found
Rectang (R), triang (T) distr


